Integrate Large Language Models in your project with LangChain #1


Integrating Large Language Models in your business is challenging.
The main pain points are:
- Existing systems - most systems were not designed to handle the amounts of data ingested and outputted by LLMs.
- Bias: if a biased LLM is asked, "Who is better at [task]?", it might respond, "[specific group] is better." because it has been trained on data that contains unfair stereotypes.
- Hallucination: when LLM generates a response not grounded in training data - e.g. if asked "What is the capital of Mars?" it might answer "The capital of Mars is Olympus, a bustling city with a vibrant Martian culture"
- Privacy and Security: to fully utilize the power of LLMs in a business context they need to be (re)trained on your data, which may include your user's PII and other sensitive data. It is your responsibility to implement security measures.
- Cost: It is a significant challenge, especially for SMBs, you need to ensure that your budget is planned for infrastructure, software, and maintenance.
On the bright side, we all expect that due to competition and technological advancements, the costs of training and running LLMs will be decreasing.
Ark Invest forecast costs to train GPT-3 level model will continue decreasing from $450000 in 2022 to 30$ in 2030
Standford fine-tuned Alpaca 7B from LLaMA 7B to GPT-3 level performance for less than $600
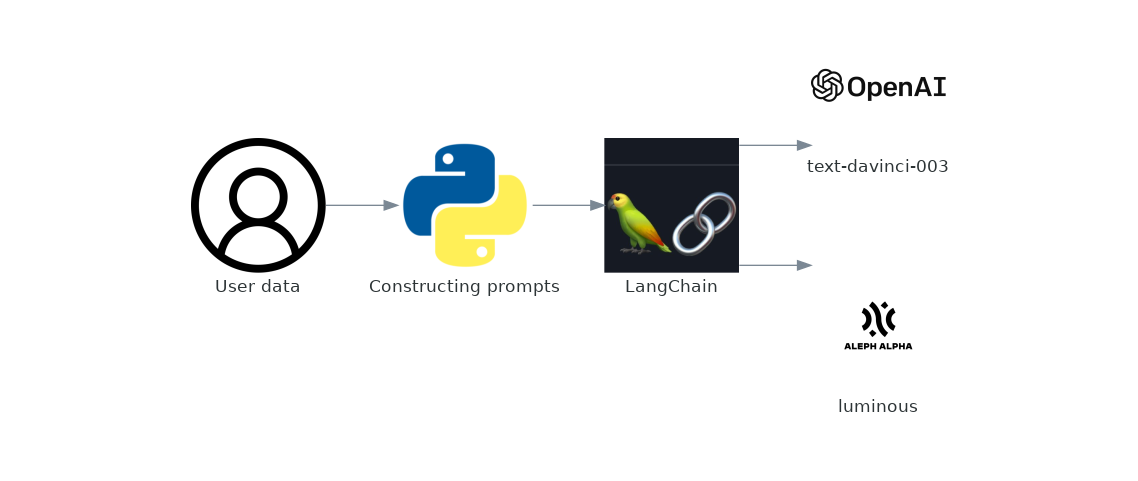
It is tempting to integrate one LLM, best suited to your project at the time e.g. GPT-3.5, directly into your codebase, but later down the road you will inevitably experience vendor lock-in and costs of switching LLM providers will be quite high.
Today I will show you one cost-effective solution to reduce the risks of vendor lock-ins by using langchain, an open-source MIT-licenced library that facilitates the development of applications with LLMs.
The code is listed below and in Google Colab